Peeking Inside Gigantic ZIPs with Only Kilobytes
I fell into this because I was curious: could I look inside a giant ZIP without downloading the whole thing? That question took me into the guts of the ZIP format, where I learned there’s a tiny index at the end that points to everything else. Once you see that, the whole file starts to feel like a book with a really helpful table of contents.
ZIP Architecture
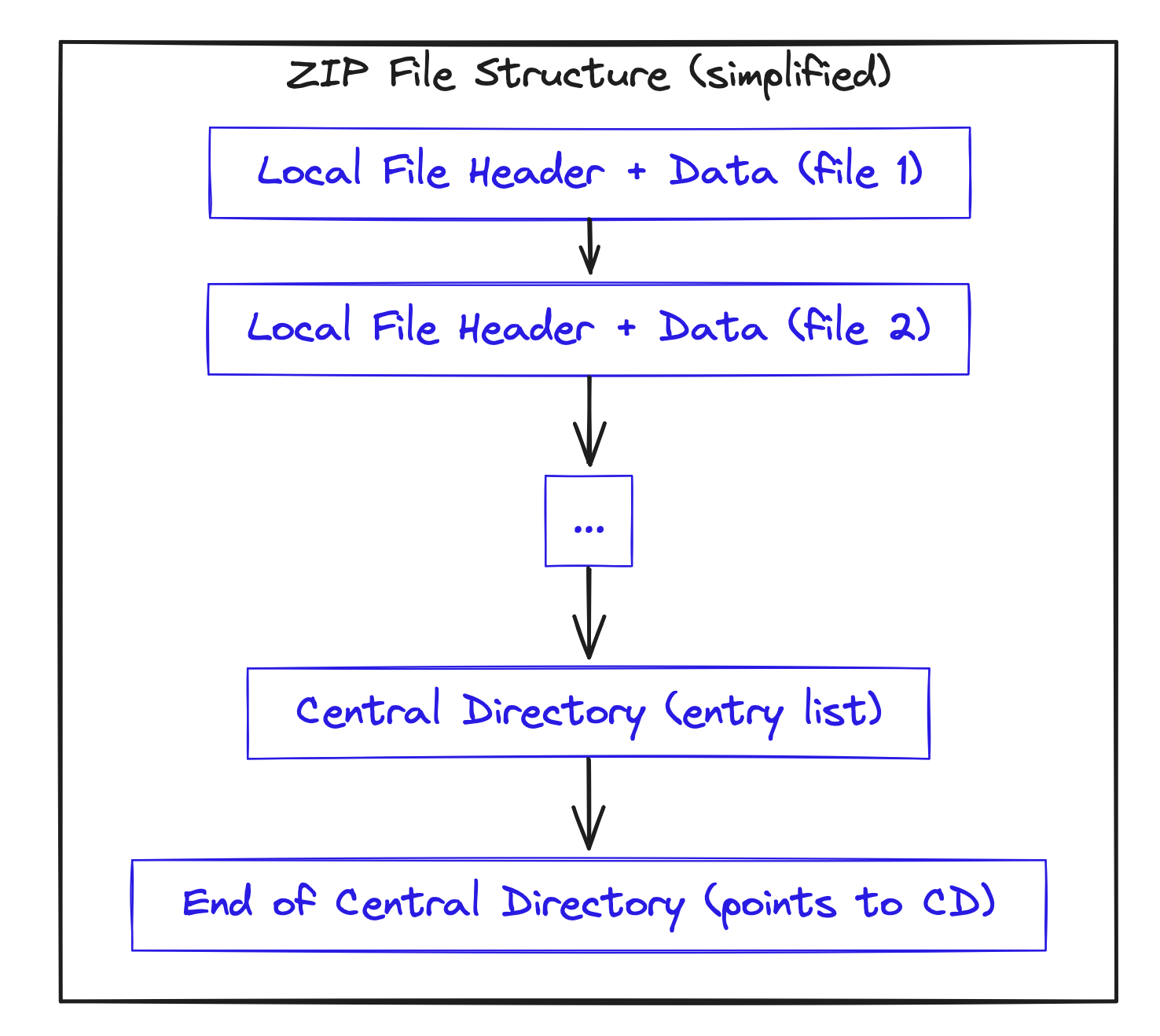
Here’s the mental model I carry now: ZIPs are a stack of per‑file records, and then an index at the end that tells you what’s inside and where to find it.
Local File Records
For each file: a Local File Header (LFH) + compressed data.
The LFH includes version, flags, compression method, timestamps, CRC, compressed/uncompressed sizes (sometimes deferred), and variable-length name/extra fields.
Central Directory (CD)
A compact list of “pointers” to each file: name, sizes, compression method, and the offset of its LFH. Exists once, near the end, after all file data.
This is the “table of contents.” Read this part, and you know all filenames, sizes, and where each file’s bytes live.
End of Central Directory (EOCD)
A short trailer that says: how many entries exist, where the CD starts, and how big it is. Signature: 0x06054b50; minimum size 22 bytes; may be followed by an optional comment.
Think of EOCD as the sticky note at the very end that says: “The index starts at page X, it’s Y pages long, and there are Z items.”
Notes:
- EOCD holds: centralDirOffset, centralDirSize, totalEntries.
- Each CD entry holds: name, sizes, localHeaderOffset.
Demo: Inspecting ZIPs with Just a Few HTTP Range Requests
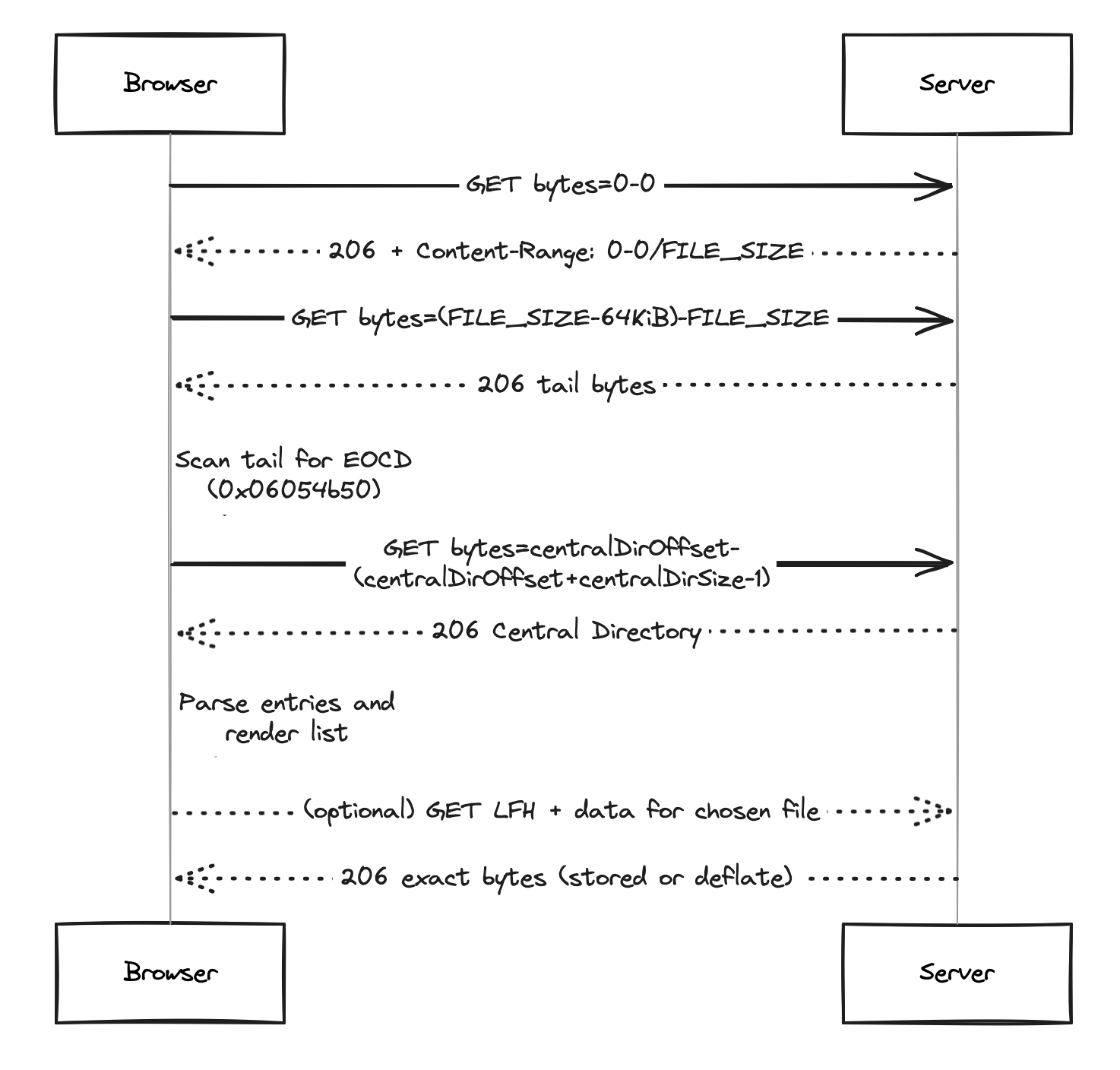
I wanted to try this idea in the browser. The trick is simple: ask the server for only the bytes we need.
-
Learn the size (a tiny poke)
- I request just the first byte (Range: bytes=0-0). The response includes a header that reveals the full size.
-
Peek at the end (where the secrets are)
- I fetch a small “tail” window (usually 64 KiB). I scan backwards for the EOCD signature. When I find it, it tells me exactly where the Central Directory starts and how big it is.
-
Fetch the index, not the payload
- Using those two numbers, I fetch just the Central Directory. That’s the index. I read each entry’s name, sizes, and a pointer to its local header.
-
Show the list
- With that, I can render a neat table of everything inside the ZIP without touching the actual file contents.
-
Download only what I want (optional)
- If I click a file, I jump to its local header to find where its data really starts (names and “extra” fields can vary). Then I read exactly the compressed bytes for that one file. If the browser supports it, I decompress on the fly; otherwise I just download the compressed stream.
Writers can keep appending files, then write the index at the end. Readers like us can jump straight to that index, and then hop to any file by offset.
Notes and edges I keep in mind:
- Some ZIPs are huge (ZIP64) and use extended 64‑bit fields; the same ideas apply, with larger numbers and a couple of extra records.
- A ZIP can include a long comment after EOCD; if I don’t see EOCD in the last 64 KiB, I widen the scanning window.
- On the web, this works when the server supports HTTP Range and exposes the right headers (like Content‑Range) to scripts.
How the browser talks to the server (sequence)
That’s it. A few tiny HTTP requests, and suddenly a multi‑gigabyte archive becomes a quick, readable story.
Source code for browser-demo: https://github.com/ritiksahni/zip-over-range
A ZIP file read backwards is like an open book.